이 글이 도움되셨다면 광고 클릭 부탁드립니다 : )
오늘은 이미지 클러스터링 방법론 중에 2017년 ICCV에 게재된 Deep Adaptive Image Clustering 논문을 리뷰해보려고 합니다. github에 코드도 공유되어서 가볍게 돌려보기도 좋습니다.
기존의 방법들과 어떤 게 다른지, 성능은 어떤지에 대해 간략하게 알아보도록 하겠습니다.
이번 포스팅에 사용된 사진과 문서는 모두 DAC 논문과 저자 발표 자료에서 발췌하였습니다.
0. basic approach
가장 일반적인? 기본적인? 이미지 군집화 방법은 CNN류의 레이어로 이미지들의 feature를 추출하고 그 feature들로 tabular 데이터에 사용하는 k-means와 같은 군집화 방법론을 적용하는 것입니다.

이 사이에 PCA를 추가해서 이미지 feature의 차원을 축소하는 방법도 많이 활용되고 있는 것 같습니다.
뒤에서 다시 언급하겠지만 이러한 방법의 단점은 feature가 한번 추출되면 끝!이라는 점입니다. classification 문제 같으면 결과를 보면서 parameter를 성능이 좋아지는 방향으로 업데이트를 할 수 있는데 말이죠.
1. Deep Adaptive Image Clustering
자 그럼 DAC에서는 이미지 클러스링 방법을 어떻게 풀어갔을까요?
논문을 읽어보니 두 가지 포인트가 있었는데 하나씩 살펴보겠습니다.
1.1 binary pairwise classification
가장 핵심이 되는 아이디어는 image clustering 문제를 binary-pairwise classification 문제로 풀어나간다는 점입니다.
기존 클러스터링 방법은 각각의 샘플을 어떤 그룹(개, 고양이, 소)에 속하게 할지 고민을 한다면, binary pairwise classification은 딱 두 개의 그룹으로만 분류합니다.
두 개의 이미지가 같은 그룹인지/ 다른 그룹인지를 분류하면, 미리 설정한 그룹의 수 k만큼의 그룹을 만들고 각 그룹 안에는 같은 그룹으로 분류된 이미지들이 들어가게 되는 컨셉입니다.

binary-pairwise classification으로 어떻게 푸는지 objective f. 을 살펴보겠습니다.

DAC는 두 이미지가 같은 그룹이면 similarity를 크게, 다른 그룹이면 similarity를 작게 하도록 w를 학습하게 됩니다.
similarity는 $g$함수로 계산하는데 이는 각 이미지의 CNN 모델 결과의 내적?으로 계산합니다.

unknown binary variable인 $ r_{ij} $는 아래와 같이 threshold를 기준으로 같은 그룹인지, 다른 그룹인지, None인지로 값을 가집니다. 모델이 학습하면서 $u(\lambda)$는 점점 작아지게, $l(\lambda)$는 점점 커지다가 같아지면 학습이 멈추게 됩니다.

1.2 Adaptive learning
The learned features are fixed, the representations can not be further improved to obtain better performance.
DAC를 설명하는 저자의 발표하는 자료에서는 이렇게 표현하고 있는데요, 위에서 소개한 basic 한 방법은 한번 학습하면 끝이라며 한계를 지적하고 있습니다. 그래서 해당 논문에서는 pareameter를 optimization 하기 위해 adaptive 하게 모델을 학습해나갑니다. 또한 그 과정을 single-stage method로 풀어나가 학습을 간소하게 했다고 합니다.

1.3 Flowchart
전체적인 DAC의 flow는 다음과 같습니다.

2. Perforamance
13가지 방법론들과 비교한 것 중 k-means도 보이네요. 현재 이미지 클러스터링의 SOTA는 DAC는 아니지만 그렇다고 아예 순위 밖으로 밀려나지는 않은 상태입니다.
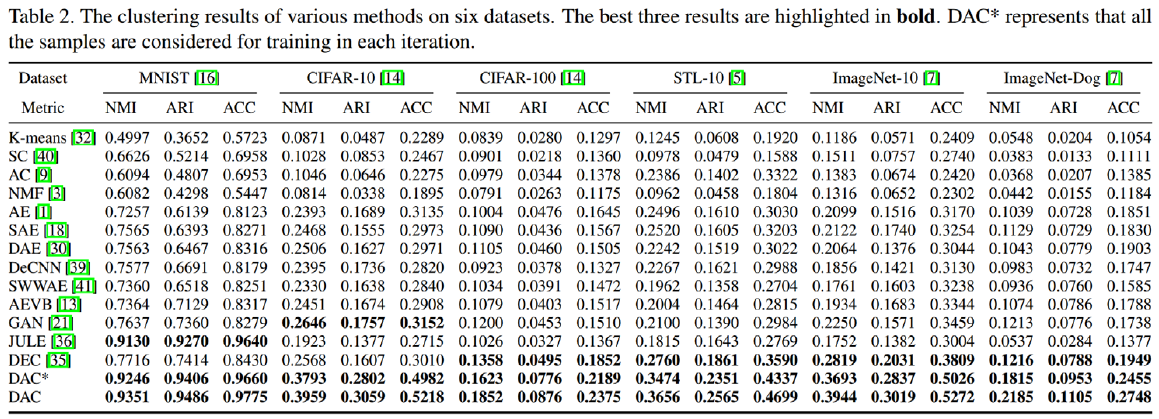
아래 github 링크 공유해두었으니, 궁금하신 분들은 직접 돌려보시면 좋을 것 같습니다 : )
참고로, 방법론을 찾다 보면 SOTA라는 단어가 종종 보이는데 각 데이터셋에서 현재 최고의 성능을 보이는 방법론을 SOTA라고 한다고 합니다. 관련 사이트를 알게 되어 함께 공유드립니다.
[참고]
SOTA(State Of The Art) 사이트
https://paperswithcode.com/sota?fbclid=IwAR16wLSr-BAcl-eZAwMVIHdsmpgBF6dN4ETR5kRGg02f_5xBBOlN6uMapo4
Papers with Code - Browse the State-of-the-Art in Machine Learning
4776 leaderboards • 2222 tasks • 4001 datasets • 46964 papers with code.
paperswithcode.com
VGG16기반 이미지 클러스터링 파이썬 예제
https://towardsdatascience.com/how-to-cluster-images-based-on-visual-similarity-cd6e7209fe34
How to cluster images based on visual similarity
Use a pre-trained neural network for feature extraction and cluster images using K-means.
towardsdatascience.com
DAC github
https://github.com/vector-1127/DAC
vector-1127/DAC
clustering. Contribute to vector-1127/DAC development by creating an account on GitHub.
github.com
'Review > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] 정형 데이터를 위한 딥러닝 | Tabnet (1) | 2022.10.19 |
|---|---|
| [논문 리뷰] 페이스북 시계열예측 모델 | prophet (1) | 2022.10.19 |
| [논문 실습] 페이스북 시계열예측 모델 | prophet with 제주도 관광객 예측 (1) | 2022.10.19 |
| [논문 리뷰] 이상치 탐지 | Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection (0) | 2022.10.19 |
| [논문 리뷰] Helical time representation to visualize return-periods of spatio-temporal events(2017) (0) | 2022.10.19 |