[도서 리뷰] XAI 설명 가능한 인공지능, 인공지능을 해부하다
아무리 잘 예측을 하는 모델을 만든다 해도 왜 그런지 설명을 못 하는 모델은 무쓸모...이지 않나 생각이 듭니다.
주장에는 근거가 필요하듯 모델 결과에도 사람이 납득할 만한 이유가 필요합니다.
그래서 저도 XAI, Explainable Artificial Intelligence에 대해 공부해보고자 책을 하나 새로 샀습니다.
| XAI 설명 가능한 인공지능, 인공지능을 해부하다국내도서저자 : 안재현출판 : 위키북스 2020.03.27 |
XAI 관련 도서는 이것밖에 안 보여서 사 오긴 했는데, XAI가 나온 배경부터 현재 통용되는 방법들에 대한 간단한 소개와 함께 실습하는 형태로 이루어져 있습니다.
(다만... 뭔가 설명이 잘못된 부분이 있는 것 같은데... 나도 잘 모르니 skip...)
0. 이야기를 열며
XAI 프로젝트가 생성된 배경에 대해 소개합니다(냉전... 스푸트니크 쇼크... 나사... 아르파.. 다르파...).
여하튼 본격적인 XAI 프로젝트는 과학적 이상을 실체화하며 실현 불가능한 일에 도전하는 다르파(Defense Research Projects Agency)에서 2016년 여름에 시작된 프로젝트(~2021년)라고 하네요.
하지만 XAI라는 단어는 1975년에 처음 등장한 용어라고...
책 설명이 목적인 글이 아닌 관계로 모두 넘기고 바로 XAI방법론에 대해서 알아보겠습니다.
이 책에서 정리하는 XAI 방법론은 6가지 정도로 정리할 수 있습니다.
1. 피처 중요도(Feature Importance)
2. 부분 의존성 플롯(PDP, Partial Dependence Plots)
3. 대리분석
3.1 글로벌 대리분석(Global Surrogate Analysis)
3.2. LIME, Local Interpretable Model-agnotic Eaplanations
4. SHAP, SHapley Additive exPlanations
5. 필터 시각화(Filter Visualization)
6. LRP, Layer-wise Relevence Propagation
1. 피처 중요도
피처 중요도, Feature Importance 혹은 Puermutation Importance는 특정 피처의 임의의 값으로 치환했을 때 원래 데이터보다 예측 에러가 얼마나 더 커지는지를 측정하는 방법입니다.
이 방법은 관심 있는 변수가 독립적일 때 잘 계산되고, 방향이 없다는 한계가 있습니다. 따라서 양의 영향력인지 음의 영향력인지 알 수 없고, 피처 간 의존성이 조금이라도 존재할 경우 결과를 신뢰할 수 없다고 합니다.

2. 부분 의존성 플롯(PDP)
부분 의존성 플롯은 피처의 수치를 선형적으로 변형하면서 알고리즘 해석 능력이 얼마나 증가하고 감소하는지를 관찰하는 방법입니다.
간단히 설명하면, 관심 있는 $X_s$변수를 고정하고 나머지 변수 $X_c$들의 조합했을 때의 평균 예측값을 계산하는 방식입니다. 단 변수 $X_s$와 $X_c$의 상관관계가 적다는 가정을 만족해야 합니다. 이 가정을 위배하게 된다면 PDP는 $X_c$에 의존적이게 그려지게 됩니다.
예제를 가져와보면, 아래의 그림은 당뇨병 진단에 대한 Glucose의 영향력을 알아보기 위한 PDP입니다. 여기서 각 각의 파란 선들은 Glucose 변수를 고정시킨 뒤, 다른 변수들과의 조합으로 나오는 예측값이고(Individual Conditional Expectation), 그것들의 평균인 노란선이 PDP가 됩니다. 해석을 해보면, 당뇨병 진단은 Glucose 높아질수록 당뇨병 진단 확률이 높아지는 것을 확인할 수 있습니다.

PDP는 이렇게 계산과정이 직관적이고 해석이 명확하다는 장점이 있지만, PDP에서 현실적으로 표현할 수 있는 최대 피처의 수는 2개이고 앞서 언급한 가정을 만족해야 한다는 한계가 존재합니다.
3. 대리분석
대리분석에는 글로벌과 로컬이 있음...
대리분석은 본래 인공지능 모델이 너무 복잡해서 분석이 불가능할 때 유사한 기능을 흉내 내는 인공지능 모델 여러 개를 대리로 만들어서 본래 모델을 분석하는 기법이라고 합니다.

대리분석은 모델 f보다 1) 학습하기 쉽고 2) 설명 가능하며, 3) 모델 f를 유사하게 흉내 낼 수 있는 모델 g를 이용하는 방법입니다.
여기서 모델 g를 학습시킬 때 데이터 전체/일부를 사용하면 글로벌, 학습 데이터 하나를 학습하는 것이 로컬 대리 분석이라고 합니다.
(여기서부터는 책 말고 아래 참고 사이트 바탕으로 작성)
3.1 글로벌 대리 분석
글로벌 대리 분석은 전체 데이터를 사용해 블랙박스 f를 따라 하는 유사 함수 g를 여러 개 만들고 가장 유사한(모델 f가 예측한 결과와) 모델 g를 선정하여(ex, R-squared) 해석하는 방법입니다. 모델 g는 의사결정 트리도 가능하고 선형 회귀, 로지트기회귀, 나이브베이즈, k-nn 등이 될 수 있습니다.
당연한 얘기겠지만, 블랙박스 모델의 성능이 좋지 못하면 대리모델의 결과는 아무 의미가 없게 됩니다.

3.2 LIME
로컬 대리분석은 글로벌 대리분석과는 달리 개별 예측을 설명하기 위한 대리모델을 학습하는데 초점을 맞춥니다.
간단하게는 관심 있는 데이터에 약간의 변화(perturb)를 줬을 때, 블랙박스 모델의 예측값이 어떻게 변하는지는 관찰하여(그걸 닮은 대리모델로) 결과 예측에 영향을 미치는 부분을 찾아내는 방법입니다.

변화는 데이터 형식에 따라 다른데 텍스트나 이미지의 경우엔 단일 단어나 슈퍼 픽셀을 켜거나 꺼서 변화를 주고
table형식 데이터는 각 변수의 평균, 표준편차를 따르는 정규분포에서 샘플을 뽑습니다.
table형식 데이터를 변형하는 과정은 아래의 그림으로 설명할 수 있습니다.
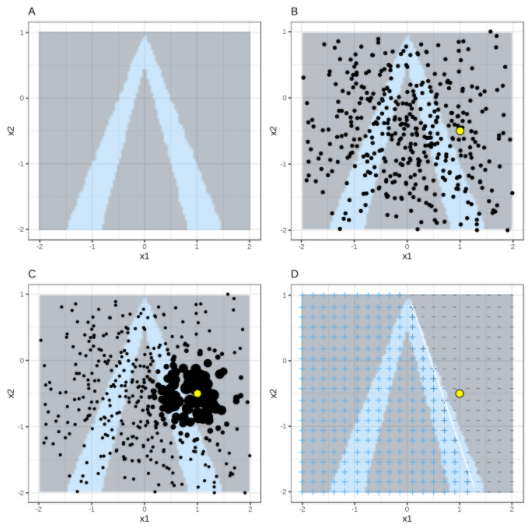
A) X1, X2 두 개의 변수로 예측하고, 회색은 예측 1이고 하늘색은 예측 0이라고 하겠습니다(블랙박스 모델 결과).
B) 우리가 관심 있는 노란 점과 정규분포로 뽑은 검은점이 있습니다.
C) 노란점 근처의 샘플에 더 큰 가중치를 부여합니다.
D) 가중된 샘플로 locally 학습된 모델(선형 회귀)의 결과입니다.
관심 있는 데이터와 가까운 영역에서 블랙박스 모델과 비슷하게 행동하기 때문에 해당 결과에 대한 설명을 할 수 있습니다.
4. SHAP
SHAP은 변수들의 값의 변화에 따라 예측 결과가 어떻게 변하는지에 집중(공헌도)하여 각 데이터의 예측 결과를 설명할 수도 있고, 변수들이 예측에 전반적으로 어떤 영향을 미치는지도 알 수 있습니다.
(이론은 나중에 추가...)
해석하는 방법을 알아보기 위해, 자궁경부암의 위험을 예측하는 사례를 살펴보겠습니다.
개별 데이터 해석을 위해 아래와 같은 force plot을 확인할 수 있는데,
해석을 해보자면 해당 여성이 자궁경부암이 확률은 0.06이고 STD가 자궁경부암이 걸릴 확률을 높이지만 years와 같은 변수가 그 증가 효과를 상쇄합니다.

SHAP분석을 진행하면 다음과 같은 Feature Importance plot도 확인할 수 있는데,
Feature Importance는 각 데이터의 각 변수의 공헌도의 절댓값의 평균(Shapley value의 절대값 평균)으로 나타내어집니다.
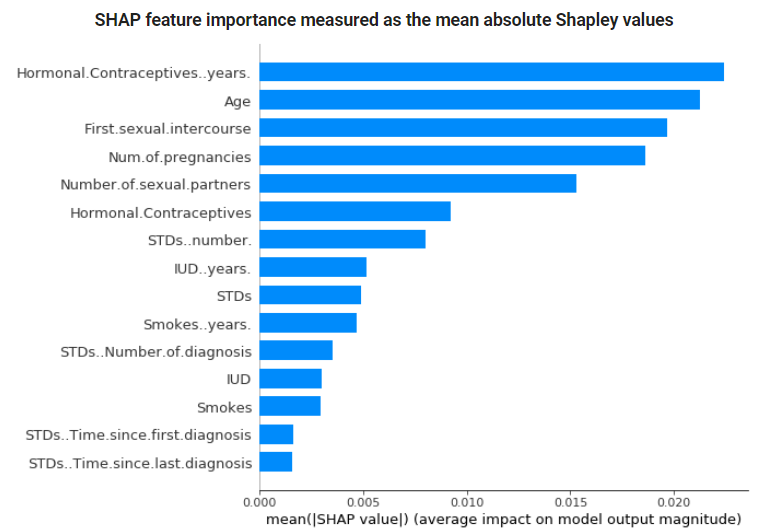
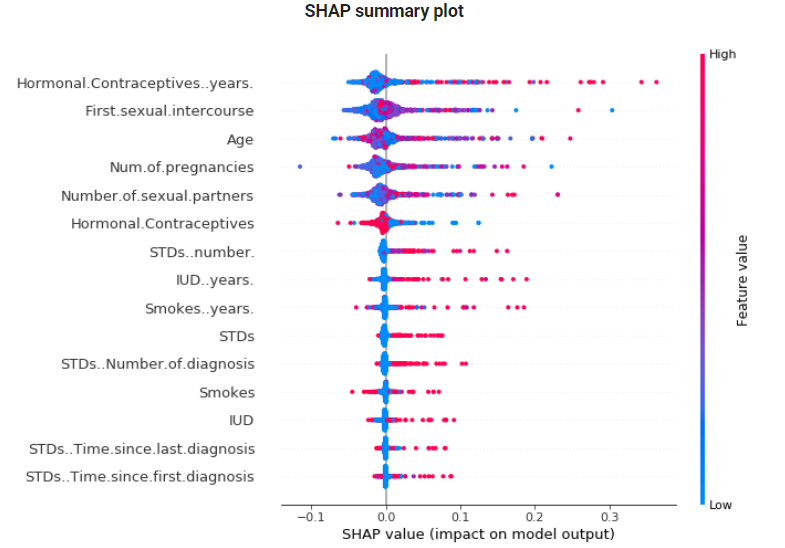
SHAP Summary plot은 Feature Importance와 Feature Effects를 결합한 plot으로 각 point들은 변수(y축)에 대한 Shapley value(x축)와 각 변수의 value(색상)을 나타냅니다.
아래 plot을 해석해보면, Feature Importance는 Hormonal... years가 가장 높으며(shapley value 절댓값 평균), year가 높을수록 자궁경부암에 걸릴 확률을 증가시킨다라고 해석할 수 있습니다.
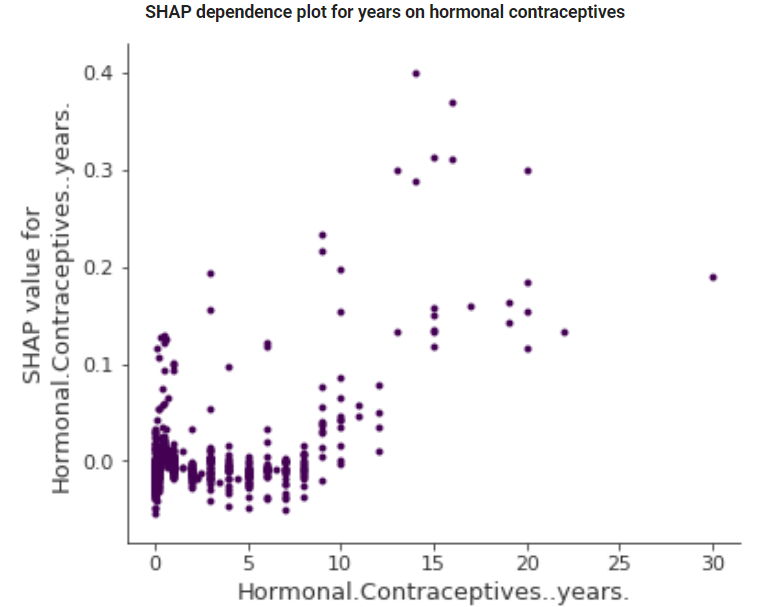
SHAP Dependence plot도 확인할 수 있는데, 이 plot은 바로 위의 plot에서 하나의 변수만 가져와서 본다고 생각하면 될 것 같습니다.
색상으로 나타내던 변수의 값을 x축으로 두면서 좀 더 데이터를 자세히 들여다볼 수 있습니다.
앞서 해석한 결과와 마찬가지로 year가 높아질수록 암에 걸릴 확률은 증가한다고 할 수는 있겠지만, 마냥 선형적인 관계는 아니고 복용 기간에 5년 미만인 사람들이 굉장히 많다는 점도 해석에서 활용할 수 있을 것 같습니다.
이렇게 Dependence plot은 각 변수의 데이터가 어떻게 분포하는지 알 수 있습니다.
참고하면 좋은 사이트
christophm.github.io/interpretable-ml-book/
Interpretable Machine Learning
Machine learning algorithms usually operate as black boxes and it is unclear how they derived a certain decision. This book is a guide for practitioners to make machine learning decisions interpretable.
christophm.github.io
(한글 번역 사이트)
역자의 말
Interpretable Machine Learning
tootouch.github.io
LIME 설명
dreamgonfly.github.io/blog/lime/
머신러닝 모델의 블랙박스 속을 들여다보기 : LIME | Dreamgonfly's blog
머신 러닝 모델에 대해서 예측의 이유를 설명하는 것은 어렵습니다. 모델이 복잡해질수록 예측의 정확도는 올라가지만, 결과의 해석은 어려워지죠. 그렇기 때문에 많은 머신 러닝 모델들이 블
dreamgonfly.github.io